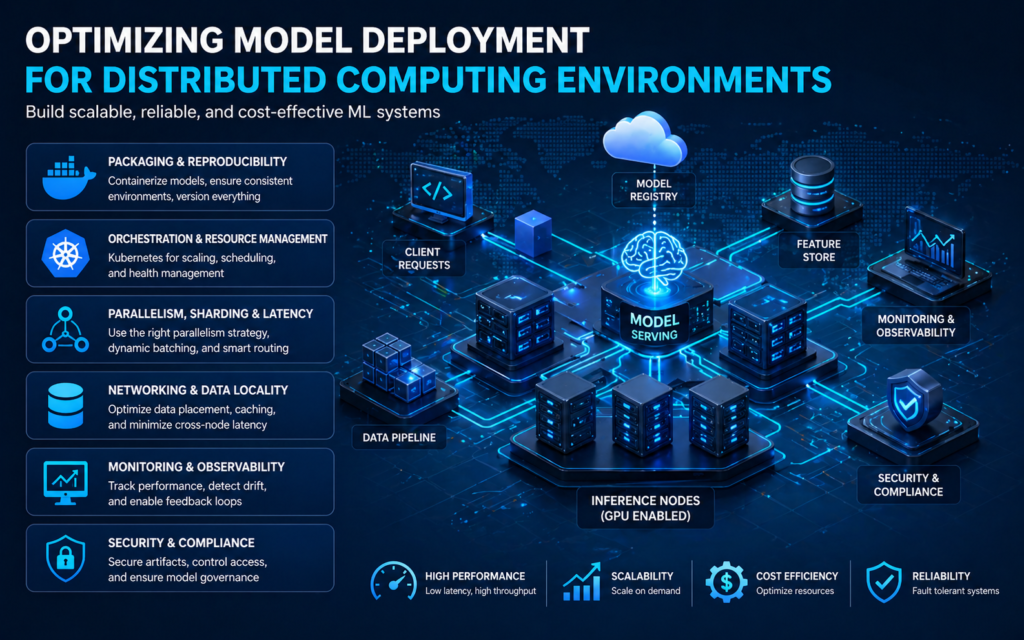
Deploying machine learning models at scale requires more than shipping a trained artifact to a server. Distributed computing environments bring opportunities for high throughput and low latency, but they also introduce complexity that must be managed deliberately. This article explores practical strategies for packaging, orchestrating, and maintaining models across clusters, emphasizing reliability, performance, and cost-effectiveness.
Packaging and Reproducibility
A consistent artifact is the foundation of reliable deployment. Containerization with lightweight images ensures that the runtime, dependencies, and drivers remain identical across nodes. Create single-purpose images that encapsulate the model binary, inference code, and a minimal runtime. Build images deterministically, version them, and store them in a private registry alongside metadata that describes hardware requirements and expected input shapes. Reproducibility also depends on deterministic preprocessing and well-documented configuration. Keep configuration as code and bake environment checks into startup scripts so misconfigured nodes fail fast rather than slowly corrupting production metrics.
Orchestration and Resource Management
Kubernetes has become the de facto orchestration layer for distributed model serving because it provides native primitives for service discovery, scaling, and health checks. Use pod anti-affinity rules to avoid colocation of critical replicas on the same physical host, and employ node selectors or custom schedulers when GPUs or specialized accelerators are required. Leverage resource requests and limits to inform the scheduler and avoid noisy neighbor scenarios. For very large models, consider a hybrid approach where the control plane runs on general-purpose nodes while inference instances occupy GPU-accelerated nodes. Autoscaling policies should be based on application-level signals such as request latency percentiles and queue lengths, not just CPU utilization.
Parallelism, Sharding, and Latency Control
Different models require different parallelism strategies. Data parallelism, where multiple replicas process separate requests, is straightforward and effective for many workloads. Model parallelism and sharding become necessary for massive models that exceed a single device’s memory. Implement sharding with careful attention to communication overhead; use high-throughput interconnects and efficient serialization protocols to minimize the cost of cross-shard exchanges. To control latency, combine asynchronous prefetching, dynamic batching, and smart request routing. Dynamic batching improves throughput by grouping small requests into larger GPU-friendly batches, but it can introduce added latency for individual requests; therefore, expose latency budgets in routing logic and adapt batch formation accordingly.
Networking, Data Locality, and Storage
Network topology influences both cost and performance. Keep frequently accessed model parameters and embedding tables close to inference nodes to reduce cross-rack traffic and improve tail latencies. Use local caching layers for model files and hot datasets, and prefer read-optimized stores for inference inputs. When models require access to large feature stores or time-series data, co-locate compute with storage or use edge caches to reduce round-trip times. For streaming inputs, adopt protocols that minimize serialization overhead and favor binary formats designed for speed. Implement graceful degradation strategies so that when remote stores are transiently unavailable, the system can serve approximations or stale-but-validated snapshots.
Continuous Delivery and Testing
Continuous integration and continuous deployment pipelines must extend to distributed environments. Testing should include unit tests, integration tests, and end-to-end tests executed against a production-like cluster. Canary deployments reduce risk by routing a small fraction of traffic to new models and comparing key metrics with the incumbent. Blue-green deployments can facilitate rollback if regressions occur. Automated chaos experiments that simulate node failures, network partitions, and resource exhaustion help validate resilience assumptions. Maintain clear observability around model metrics such as accuracy drift, input distribution shifts, and calibration errors so pipelines can trigger retraining or rollback actions automatically.
Monitoring, Observability, and Feedback Loops
Operational visibility is essential for distributed deployments. Collect granular telemetry including request latencies, per-replica error rates, GPU utilization, and model-specific metrics like prediction confidence distributions. Aggregate traces to understand end-to-end latency contributions and use sampled logging to diagnose outliers. Establish alerting thresholds for both infrastructure and model performance anomalies. Closed-loop feedback systems that route production data back into training pipelines enable timely model updates and detection of dataset drift. Annotations and lineage metadata are crucial for tracing performance changes back to specific data versions or model checkpoints.
Cost and Efficiency Trade-offs
Scaling across a cluster amplifies costs if left uncontrolled. Reduce inference compute by quantizing models, applying pruning where acceptable, or converting to optimized runtimes that leverage hardware accelerators. Profile models to understand the trade-offs between precision and latency. Implement multi-tier serving where small, fast models handle most requests and large, expensive models are invoked for a subset of complex cases. Spot instances or preemptible VMs can lower infrastructure spend for non-latency-sensitive workloads, but design the system to handle preemptions gracefully using checkpoints and quick failover.
Security and Compliance
Deploying across distributed environments increases the attack surface. Secure model artifacts in private registries, sign images, and enforce image scanning for vulnerabilities. Control access with role-based policies and rotate credentials automatically. Since models can unintentionally leak training data, apply differential privacy and rigorously test for memorization of sensitive information. Monitor for adversarial inputs and implement rate limiting and input validation to reduce the risk of abuse. Finally, maintain audit logs mapping predictions to model versions for compliance and post-incident analysis.
Architecture Practices to Adopt
Design systems around small, composable services that isolate inference logic from preprocessing, postprocessing, and model management. Treat models as first-class deployable units and develop a catalog that exposes metadata for routing, A/B testing, and lifecycle management. Emphasize graceful degradation, reproducible builds, and robust monitoring so that the system can evolve without jeopardizing service-level objectives.
Successfully optimizing model deployment for distributed computing environments requires attention to packaging, orchestration, data locality, and observability. By combining rigorous CI/CD practices with strategies for efficient parallelism, resource-aware scheduling, and strong operational controls, teams can deliver models that are performant, reliable, and cost-effective at scale while adapting to changing workloads and infrastructure. Leveraging platforms that integrate orchestration, monitoring, and hardware acceleration simplifies implementation, and thoughtful architecture ensures long-term maintainability and agility when serving production-grade intelligent systems that go beyond a single node or machine learning instance and into a resilient distributed fabric that meets business requirements in production contexts, including emerging AI cloud offerings.